This post introduces the MapReduce framework that enables you to write applications that process vast amounts of data, in parallel, on large clusters of commodity hardware, in a reliable and fault-tolerant manner. In addition, this post describes the architectural components of MapReduce and lists the benefits of using MapReduce.
MapReduce
It is a software framework that enables you to write applications that process vast amounts of data, in-parallel on large clusters of commodity hardware in a reliable and fault-tolerant manner.
- Prior to Hadoop 2.0, MapReduce was the only way to process data in Hadoop.
- A MapReduce job usually splits the input data set into independent chunks, which are processed by the map tasks in a completely parallel manner.
- The framework sorts the outputs of the maps, which are then inputted to the reduce tasks.
- Typically, both the input and the output of the job are stored in a file system.
- The framework takes care of scheduling tasks, monitors them, and re-executes the failed tasks.
MapReduce Architecture
- Master-slave architecture
- Storing data in HDFS is low cost, fault-tolerant, and easily scalable, to just name a few.
- MapReduce integrates with HDFS to provide the exact same benefits for parallel data processing.
- Sends computations where the data is stored on local disks
- Programming model or framework for distributed computing. It hides complex “house keeping” tasks from you as developer.
MapReduce Version 1 (MRv1) Architecture
Typically, MapReduce (compute) framework and the HDFS (storage) are running on the same set of nodes. This allows the framework to effectively schedule tasks on the nodes where data is stored, data locality, which results in better performance. The MapReduce 1 framework consists of:
- One master JobTracker daemon per cluster
- One slave TaskTracker daemon per cluster-node
The master is responsible for scheduling the jobs’ component tasks on the slaves, monitoring them, and re-executing the failed tasks. The slaves execute the tasks requested by the master. MRv1 runs only MapReduce jobs.
MapReduce Phases
In Hadoop, files are made up of records that are processed later by the Mapper tasks in MapReduce. In HDFS, the default block size is 64 MB, which means that the data stored in a file are broken down into chunks of exactly 64 MB. A problem arises when the records in the file span block boundaries; that is, one record is contained in two or more HDFS blocks. HDFS has no idea of what is inside the file blocks and it cannot determine when a record might spill over into another block. To solve this problem, Hadoop uses a logical representation of the data stored in file blocks, known as input splits. When a MapReduce job client calculates the input splits, it determines where the first whole record in a block begins and where the last record in the block ends.
Map
– Each Map task usually works on a single HDFS block (input split).
– Map tasks run on the slave nodes in the cluster where the HDFS data block is stored (data locality).
– The input presented to the Map task is a key-value pair.
Shuffle and Sort
– Sorts and consolidates intermediate output data from all of the completed mappers from the Map phase
Reduce
– The intermediate data from the Shuffle and Sort phase is the input to the Reduce phase.
– The Reduce function (developer) generates the final output.
MapReduce Framework
MapReduce is a software framework that enables you to write applications that will process large amounts of data, in- parallel, on large clusters of commodity hardware, in a reliable and fault-tolerant manner.It integrates with HDFS and provides the same benefits for parallel data processing. It Sends computations to where the data is stored. The framework:
– Schedules and monitors tasks, and re-executes failed tasks.
– Hides complex “housekeeping” and distributed computing complexity tasks from the developer.
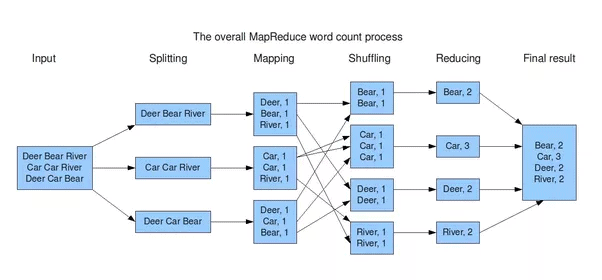
A map function generates a series of key-value pairs from the input data. This data is then reduced by a function to combine all values that are associated with equivalent keys. Programs are automatically parallelized and executed on a runtime system that manages partitioning the input data, scheduling execution, and managing communication, including recovery from machine failures.
- The records are divided into smaller chunks for efficiency, and each chunk is executed serially on a particular compute engine.
- The output of the Map phase is a set of records that are grouped by the mapper output key. Each group of records is processed by a reducer (again, these are logically in parallel).
- The output of the Reduce phase is the union of all records that are produced by the reducers.
MapReduce Jobs
Hadoop divides the input to a MapReduce job into fixed-size pieces or “chunks” named input splits. Hadoop creates one map task (Mapper) for each split. The Input split (usually an HDFS block) runs the user-defined map function for each record in the split. Hadoop attempts to run the tasks where the data is located.
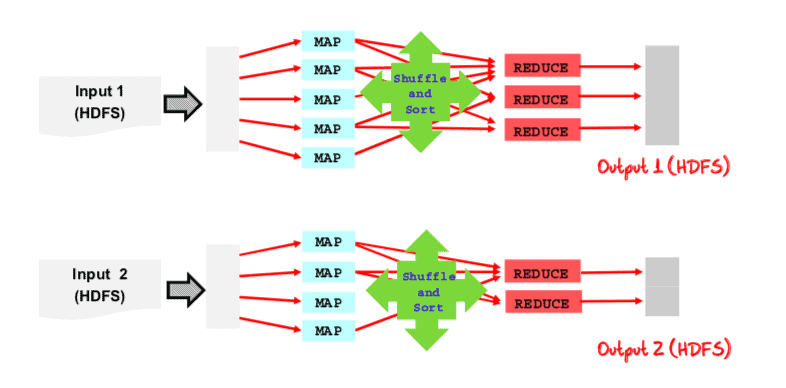
A mapper task works on one individual record (with a key-value) at a time and stores the intermediate data locally. The framework shuffles and sorts the outputs of the maps before they become the input to the reducer tasks. Typically both the input and the output of the job are stored in HDFS.
Interacting with MapReduce
Hadoop tries to run the TaskTrackers and DataNodes on the same servers. Hadoop does its best to run the map task on a node where the input data resides in HDFS. This is called the data locality optimization because it does not use valuable cluster bandwidth. Sometimes, however, all three nodes hosting the HDFS block replicas (as discussed in the earlier HDFS lesson) for a map task’s input split are running other map tasks; therefore, the job scheduler will locate a free map slot on a node in the same rack as one of the HDFS blocks. Sometimes, this is not possible; therefore, an off-rack node is used, which results in an inter-rack network transfer.
– MapReduce code can be written in Java, C, and scripting languages.
– Higher-level abstractions (Hive, Pig) enable easy interaction.
– The code is submitted to the JobTracker daemons on the Master node and executed by the TaskTrackers on the Slave nodes.