NameNode High Availability Concepts
In case of either accidental failures or regular maintenance of NameNode, the cluster will become unavailable. This is a big problem for a production Hadoop cluster.
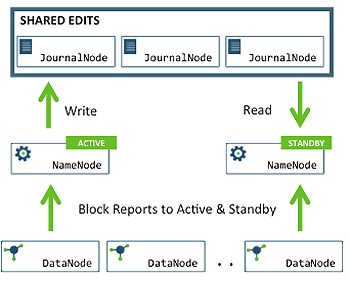
– In the cluster, there are two separate machines—the active state NameNode and standby state NameNode.
– At any point in time, exactly one of the NameNodes is in an active state, and the other is in a standby state.
– The active NameNode manages the requests from all client DataNodes in the cluster, while the standby remains a slave.
– All the DataNodes are configured in such a way that they send their block reports and heartbeats to both active and standby NameNodes.
– Both NameNodes, active and standby, remain synchronized with each other by communicating with a group of separate daemons called JournalNodes (JNs).
– When a client makes any filesystem change, the active NameNode durably logs a record of the modification to the majority of these JNs.
– The standby node immediately applies those changes to its own namespace by communicating with JNs.
– In the event of the active NameNode being unavailable, the standby NameNode makes sure that it absorbs all the changes (edits) from JNs and promotes itself as an active NameNode.
– To avoid a scenario that makes both the NameNodes active at a given time, the JNs will only ever allow a single NameNode to be a writer at a time. This allows the new active NameNode to safely proceed with failover.
When we had installed the HDP cluster we defined the nn1.localdomain host to be the primary and secondary namenode as well. In this post, we will see how to enable the NameNode HA and have a separate Standby NameNode.
Verify the current Configuration
Before proceeding, let’s verify our current configuration. Go to the services tab and check for HDFS service.
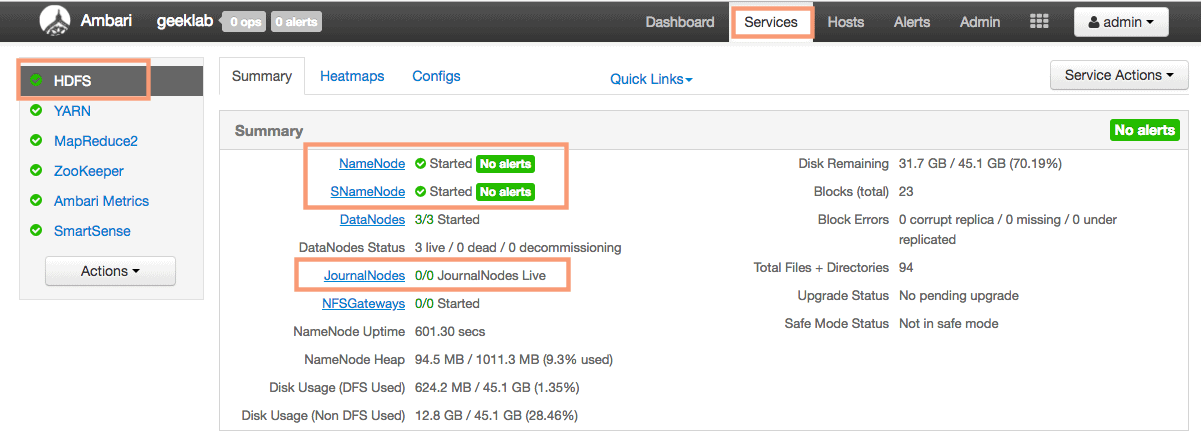
As you can see in the screenshot above, we only have a primary and secondary namenode and there are no JournalNodes. This verifies that we do not have the NameNode HA enabled currently.
Enable NameNode HA Wizard
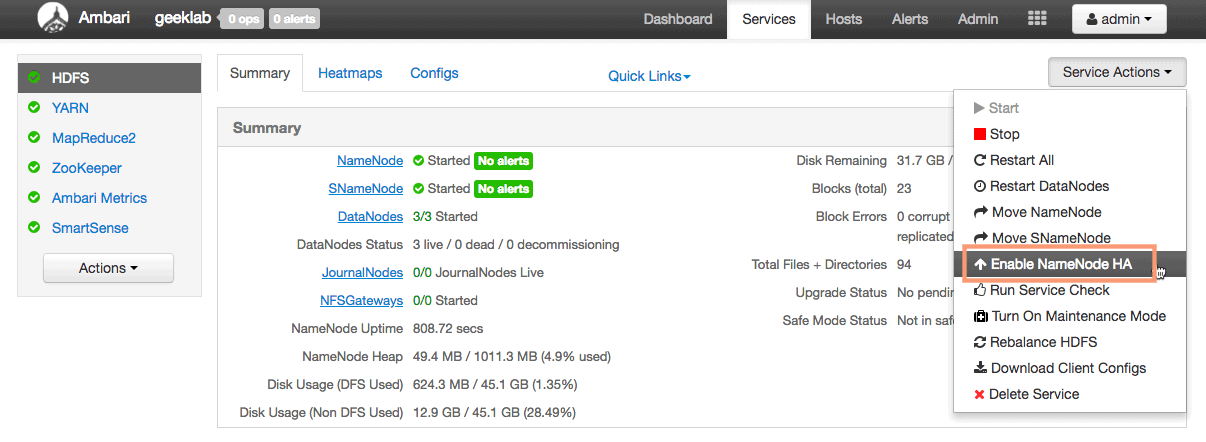
Click the “Enable NameNode HA” option under the “Service Action” drop-down to start configuring the NameNode HA. This will invoke a NameNode HA Wizard which will guide us in the configuration.
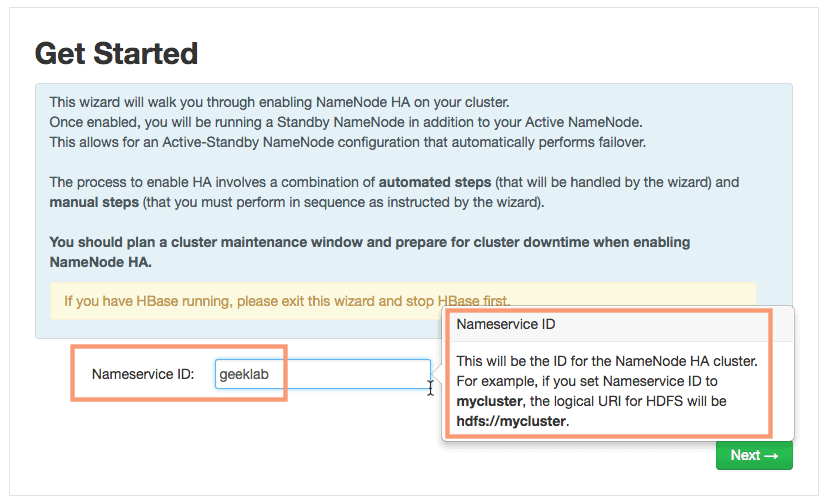
1. Get Started – Defining “Nameservice ID”
On the first page of the wizard, you will have to configure the Nameservice ID. In an HA NameNode setup, you create a logical nameservice, formally called a nameservice ID, to point to the HDFS instance, which consists of both the active and the Standby NameNodes. The logical URI for the HDFS will be hdfs://[nameservice ID].
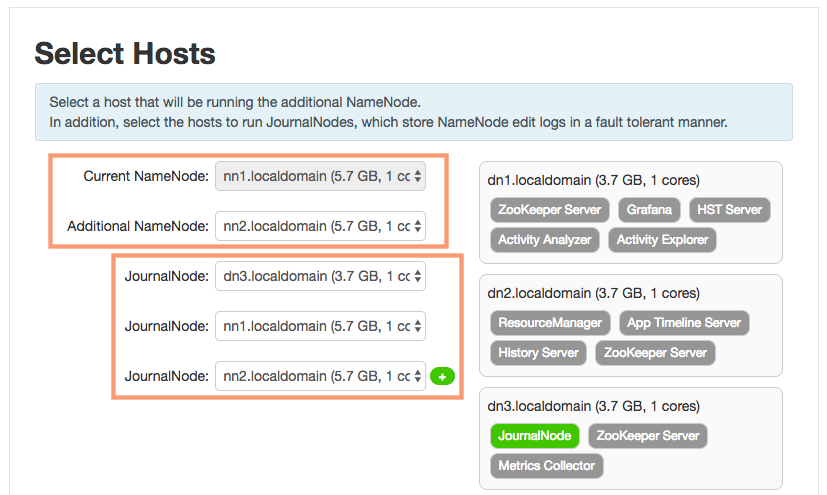
2. Select Hosts
On the next screen, we will select nn2 as our standby namenode and dn1, dn2, dn3 as the JournalNodes. JournalNodes store NameNode edit logs in a fault tolerant manner.
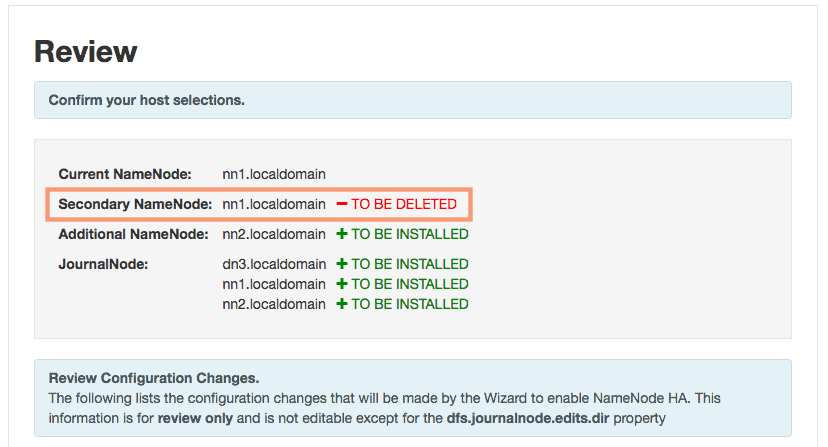
3. Review
You can review and confirm your host selection on the review page. As you can see the secondary namenode component will be deleted as it is no longer needed in a NameNode HA setup.
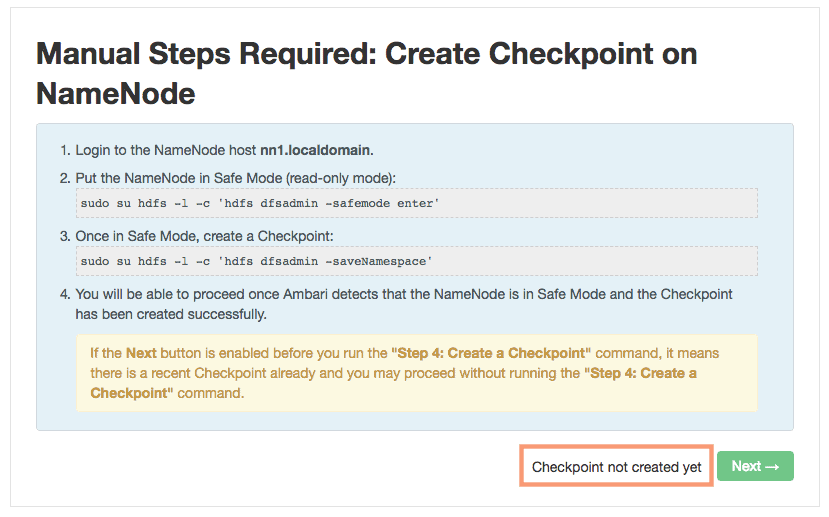
4. Manual Steps Required: Create Checkpoint on NameNode
As the next page suggest, we need to run 2 commands on the existing namenode (nn1) manually.
- To put the exiting NameNode in Safe Mode (Read Only Mode)
- To create a check Point in safe mode
[root@nn1 ~]# sudo su hdfs -l -c 'hdfs dfsadmin -safemode enter' Safe mode is ON
[root@nn1 ~]# sudo su hdfs -l -c 'hdfs dfsadmin -saveNamespace' Save namespace successful
Once you have executed the 2 commands, the ambari installer will automatically proceed with the next step in the installation.
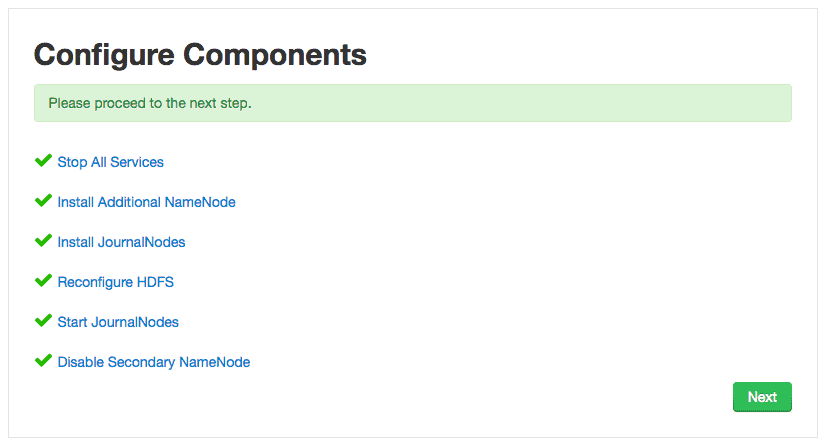
5. Configure Components
Ambari wizard will start configuring the components of NameNode HA, which includes:
- Stop All Services
- Install Additional NameNode
- Install JournalNodes
- Reconfiguring HDFS
- Start JournalNodes
- Disable Secondary NameNode
6. Initialize JournalNodes
Execute the below command on the existing NameNode nn1. This command formats all the JournalNodes. It also copies all the edits data after the most recent checkpoint from the edits directories of the local NameNode (nn1) to JournalNodes.
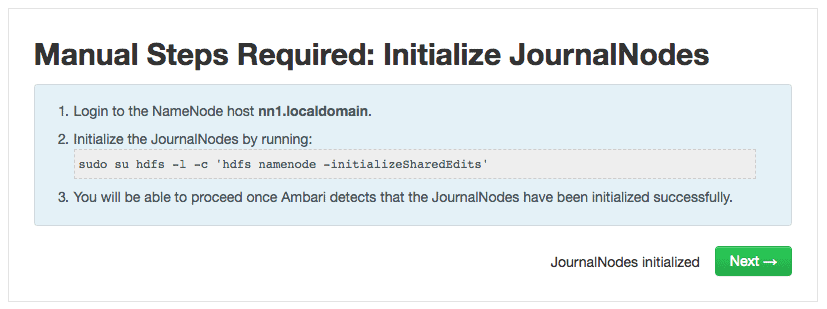
# sudo su hdfs -l -c 'hdfs namenode -initializeSharedEdits' 18/07/17 14:09:23 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: user = hdfs STARTUP_MSG: host = nn1.localdomain/192.168.1.2 STARTUP_MSG: args = [-initializeSharedEdits] STARTUP_MSG: version = 2.7.3.2.6.5.0-292 ..... (output truncated) ..... 18/07/17 14:09:27 INFO client.QuorumJournalManager: Starting recovery process for unclosed journal segments... 18/07/17 14:09:27 INFO client.QuorumJournalManager: Successfully started new epoch 1 18/07/17 14:09:27 INFO namenode.RedundantEditLogInputStream: Fast-forwarding stream '/hadoop/hdfs/namenode/current/edits_0000000000000000566-0000000000000000566' to transaction ID 566 18/07/17 14:09:27 INFO namenode.FSEditLog: Starting log segment at 566 18/07/17 14:09:28 INFO namenode.FSEditLog: Ending log segment 566, 566 18/07/17 14:09:28 INFO namenode.FSEditLog: logSyncAll toSyncToTxId=566 lastSyncedTxid=566 mostRecentTxid=566 18/07/17 14:09:28 INFO namenode.FSEditLog: Done logSyncAll lastWrittenTxId=566 lastSyncedTxid=566 mostRecentTxid=566 18/07/17 14:09:28 INFO namenode.FSEditLog: Number of transactions: 1 Total time for transactions(ms): 1 Number of transactions batched in Syncs: 0 Number of syncs: 1 SyncTimes(ms): 17 18/07/17 14:09:28 INFO util.ExitUtil: Exiting with status 0 18/07/17 14:09:28 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at nn1.localdomain/192.168.1.2 ************************************************************/
7. Start Components
The ambari wizard will start the ZooKeeper Server and NameNode server in this step.
8. Initialize NameNode HA Metadata
As part of Last setp we have to execute 2 mode commands, one on the existing NameNode (nn1) and the other on the standby NameNode (nn2).

The first command initializes HA state in ZooKeeper. This command creates a znode in ZooKeeper. The failover system stores use this znode for data storage.
# sudo su hdfs -l -c 'hdfs zkfc -formatZK' ..... (output truncated) ..... 18/07/17 14:12:16 INFO zookeeper.ZooKeeper: Session: 0x364a765cbd10003 closed 18/07/17 14:12:16 WARN ha.ActiveStandbyElector: Ignoring stale result from old client with sessionId 0x364a765cbd10003 18/07/17 14:12:16 INFO zookeeper.ClientCnxn: EventThread shut down 18/07/17 14:12:16 INFO tools.DFSZKFailoverController: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down DFSZKFailoverController at nn1.localdomain/192.168.1.2 ************************************************************/
The second command, formats StandbyNameNode (nn2) and copy the latest checkpoint (FSImage) from nn1 to nn2:
# sudo su hdfs -l -c 'hdfs namenode -bootstrapStandby' 18/07/17 21:59:21 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: user = hdfs STARTUP_MSG: host = nn2.localdomain/192.168.1.7 STARTUP_MSG: args = [-bootstrapStandby] STARTUP_MSG: version = 2.7.3.2.6.5.0-292 ..... (output truncated) ..... 18/07/17 14:13:16 INFO namenode.TransferFsImage: Image Transfer timeout configured to 60000 milliseconds 18/07/17 14:13:17 INFO namenode.TransferFsImage: Combined time for fsimage download and fsync to all disks took 0.02s. The fsimage download took 0.02s at 400.00 KB/s. Synchronous (fsync) write to disk of /hadoop/hdfs/namenode/current/fsimage.ckpt_0000000000000000565 took 0.00s. 18/07/17 14:13:17 INFO namenode.TransferFsImage: Downloaded file fsimage.ckpt_0000000000000000565 size 6938 bytes. 18/07/17 14:13:17 INFO util.ExitUtil: Exiting with status 0 18/07/17 14:13:17 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at dn2.localdomain/192.168.1.4 ************************************************************/
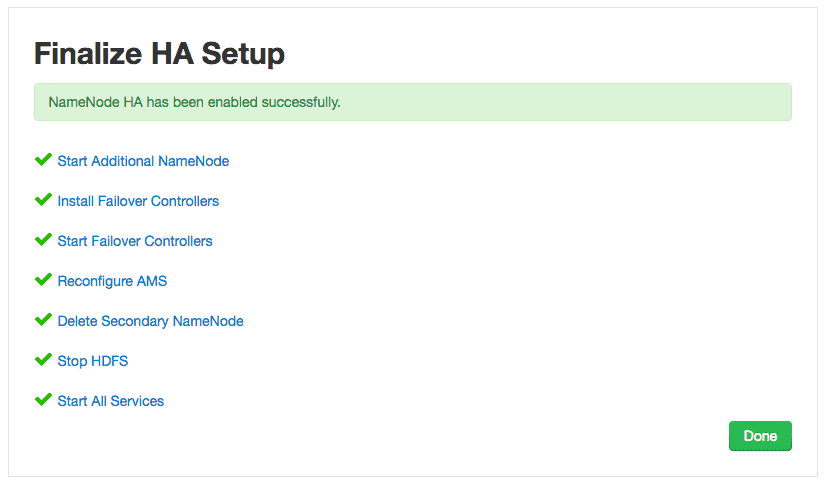
9. Finalize HA setup
Ambari wizard will finalize the NameNode HA on this page. It includes:
- Start Additional NameNode
- Install Failover Controllers
- Start Failover Controllers
- Reconfigure AMS
- Delete Secondary NameNode
- Stop HDFS
- Start All Services
Verify the NameNode HA setup
Once you are finished with the Ambari installation wizard, ambari will reload the dashboard and you can view the new configuration in effect as shown below.
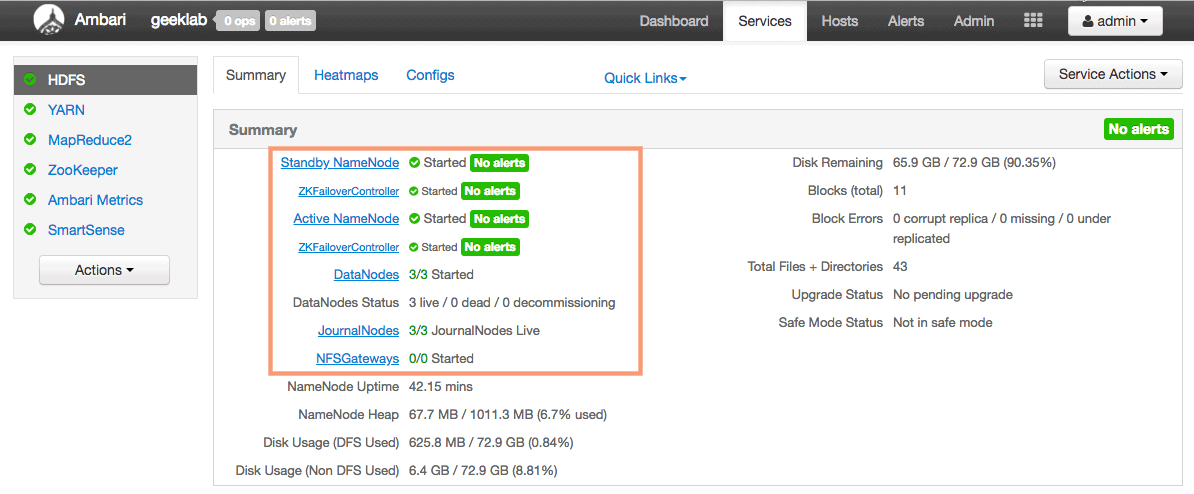
As you can see there is a Standby NameNode, ZKFailoverController and also JournalNodes present in the HDFS service page.