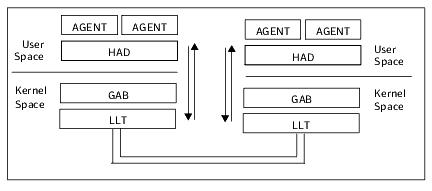
GAB, LLT and HAD forms the basic building blocks of vcs functionality. I/O fencing driver on top of it provides the required data integrity. Before diving deep into the topic lets see some basic components of VCS which contribute to the communication stack of VCS.
{kind=link}
LLT
– LLT stands for low latency transport protocol. The main purpose of LLT is to transmit heartbeats.
– GAB determines the state of a node with the heartbeats sent over the LLTs.
– LLTs are also used to distribute the inter system communication traffic equally among all the interconnects.
– We can configure upto 8 LLT links including the low and high priority links
1. High Priority links
– Heartbeat is sent every 0.5 seconds
– Cluster status information is passed to other nodes
– Configured using a private/dedicated network.
2. Low priority links
– Heartbeat is sent every 1 seconds
– No cluster status is sent over these links
– Automatically becomes high priority links if there are no more high priority links left
– Usually configured over a public interface (not dedicated)
To view the LLT link status use command verbosely :
# lltstat -nvv | more
Node State Link Status Address
*0 node01 OPEN
ce0 UP 00:11:98:FF:FC:A4
ce1 UP 00:11:98:F3:9C:8C
*0 node02 OPEN
ce0 UP 00:11:98:87:F3:F4
ce1 UP 00:11:98:23:9A:C8 Other lltstat commands
# lltstat -> outputs link statistics # lltstat -c -> displays LLT configuration directives # lltstat -l -> lists information about each configured LLT link
Commands to start/stop LLT
# lltconfig -c -> start LLT # lltconfig -U -> stop LLT (GAB needs to stopped first)
LLT configuration files
LLT uses /etc/llttab to set the configuration of the LLT interconnects.
# cat /etc/llttab set-node node01 set-cluster 02 link nxge1 /dev/nxge1 - ether - - link nxge2 /dev/nxge2 - ether - - link-lowpri /dev/nxge0 – ether - -
set-cluster -> unique cluster number assigned to the entire cluster [ can have a value ranging between 0 to (64k – 1) ]. It should be unique across the organization.
set-node -> a unique number assigned to each node in the cluster. Here the name node01 has a corresponding unique node number in the file /etc/llthosts. It can range from 0 to 31.
– Another configuration file used by LLT is /etc/llthosts.
– It has the cluster-wide unique node number and nodename as follows:
# cat /etc/llthosts 0 node01 1 node02
– LLT has an another optional configuration file : /etc/VRTSvcs/conf/sysname.
– It contains short names for VCS to refer. It can be used by VCS to remove the dependency on OS hostnames.
GAB
– GAB stands for Group membership services and atomic broadcast.
– Group membership services : It maintains the overall cluster membership information by tracking the heartbeats sent over LLT interconnects. If any nodes fails to send the heartbeat over LLT the GAB module send the information to I/O fencing module to take further action to avoid any split brain condition if required. It also talks to the HAD which manages the agents and service groups.
– Atomic Broadcast : atomic broadcast of cluster membership ensures that every node in the cluster has same information about every resource and service group in the cluster.
GAB configuration files
The file /etc/gabtab contains the command to start the GAB.
# cat /etc/gabtab /sbin/gabconfig -c -n 4
here -n 4 -> number of nodes that must be communicating in order to start VCS.
Seeding During startup
– The option -n 4 in the GAB configuration file shown above ensures that minimum number of nodes are communicating before VCS can start. Its called seeding.
– In case we don’t have sufficient number of nodes to start VCS [ may be due to a maintenance activity ], but have to do it anyways, then we have do what is called as manual seeding by firing below command on each of the nodes.
# gabconfig -c -x
Start/Stop GAB
# gabconfig -c (start GAB) # gabconfig -U (stop GAB)
To check the status of GAB
# gabconfig -a GAB Port Memberships =============================================== Port a gen a36e001 membership 01 Port b gen a36e004 membership 01 Port h gen a36e002 membership 01
Common GAB ports
a --> gab driver b --> I/O fencing (to ensure data integrity) d --> ODM (Oracle Disk Manager) f --> CFS (Cluster File System) h --> VCS (VERITAS Cluster Server: high availability daemon, HAD) o --> VCSMM driver (kernel module needed for Oracle and VCS interface) q --> QuickLog daemon v --> CVM (Cluster Volume Manager) w --> vxconfigd (module for cvm)
HAD
– HAD, high availability daemon is the main VCS engine which manages the agents and service group.
– It is in turn monitored by hashadow daemon.
– HAD maintains the resource configuration and state information.
Start/Stop HAD
– hastart command needs to be run on every node in the cluster where you want to start the HAD.
– Although hastop can be run from any one node in the cluster too to stop the entire cluster.
– hastop gives us various option to control the behavior of service groups upon stoping the node.
# hastart
# hastop -local # hastop -local -evacuate # hastop -local -force # hastop -all -force # hastop -all
Meanings of various parameters of hastop are:
-local -evacuate -> migrates Service groups on the node where it is fired and stops HAD on the same node only
-local -force -> Stops HAD leaving services running on the node where it is fired
-all -force -> Stops HAD on all the nodes of cluster leaving the services running
-all -> Stops HAD on all nodes in cluster and takes service groups offline