Let us now see various communication faults that can occur in the VCS cluster and how VCS engine reacts to these fault. There are basically 2 types of communication failures
1. Single LLT link failure (jeopardy)
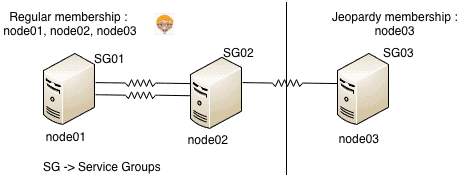
When a node in the cluster has only the last LLT link intact, the node forms a regular membership with other nodes with which it has more than one LLT link active and a Jeopardy membership with the node with which it has only one LLT link active. So as shown in the digram below node03 forms a jeopardy membership and there is also a regular membership between node01, node02 and node03.
{kind=link}
GAB Port Memberships =================================== Port a gen a36e0003 membership 012 Port a gen a36e0003 jeopardy ;2 Port h gen fd570002 membership 012 Port h gen fd570002 jeopardy ;2
Effects of Jeopardy
1. Jeopardy membership formed only for node03
2. Regular membership between node01, node02, node03
3. Service groups SG01, SG02, SG03 continue to run and other cluster functions remain unaffected.
4. If node03 faults or last link breaks, SG03 is not started on node01 or node02. This is done to avoid data corruption, as in case the last link is broken the nodes node02 and node01 may think that node03 is down and try to start SG03 on them. This may lead to data corruption as same service group may be online on 2 systems.
5. Failover due to resource fault or operator request would still work.
Recovery
To recover from jeopardy, just fix the link and GAB automatically detects the new link and the jeopardy membership is removed from node03.
2. Network partition
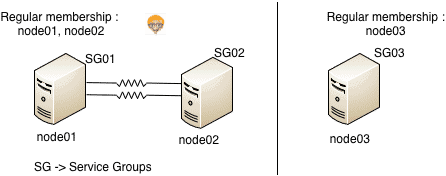
Now consider a case where the last link also fails (note that the last link fails when node03 was already in jeopardy membership). In that case 2 mini-clusters are formed.
1. New regular membership formed between node01 and node02 and a separate membership for node03
2. Two min-clusters formed, one with node01 and node02 and one only containing node03
3. As node03 was already in jeopardy membership – a) SG01 and SG02 are auto-disabled on node03
b) SG03 is auto-disabled on node01
This implies that SG01 and SG02 can not be started on node03 and SG03 can not be started on node01 or node02. But SG01 and SG02 can failover to node02 and node01 respectively.
{kind=link}
Recovery
Now if you directly fix the LLT links, there will be a mismatch in the cluster configurations of the 2 mini-clusters. To avoid this, shutdown mini-cluster with fewest nodes. In our case node03. Fix the LLT links and startup the node03. In case you fix the link without shutting down anyone mini-cluster GAB prevents a split-brain scenario by panicking mini-cluster with lowest no of nodes. In a 2 node cluster, node with higher LLT node number panics. Similarly incase of mini-clusters having same number of nodes in each mini-cluster, mini-cluster with lowest LLT node number continues to run, while other mini-cluster nodes panic.
Split Brain
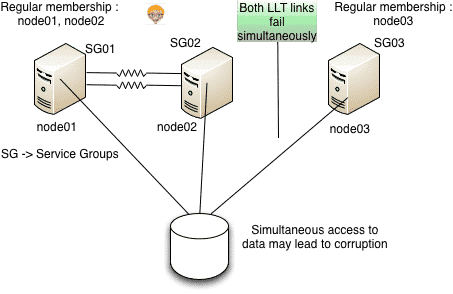
Split brain occurs when all the LLT links fail simultaneously. Here systems in the cluster fail to identify whether it is a system failure or an interconnect failure. Each mini-cluster thus formed thinks that it is the only cluster that’s active at the moment and tries to start the service groups on the other mini-cluster which he thinks is down. A similar thing happens to the other mini-cluster and this may lead to a simultaneous access to the storage and can cause data corruption.
{kind=link}
I/O fencing
VCS implements I/O fencing mechanism to avoid a possible split-brain condition. It ensure data integrity and data protection. I/O fencing driver uses SCSI-3 PGR (persistent group reservations) to fence off the data in case of a possible split brain scenario. Persistent group reservations are persistent across SCSI bus resets and supports multi-pathing from host to disk.
Coordinator disks
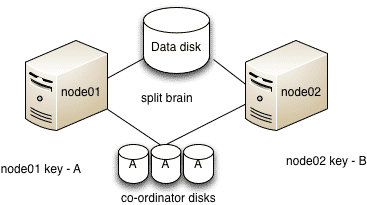
Coordinator disks are used to store the key of each host, which can be used to determine which node stays in cluster in case of a possible split brain scenario. In case of a split brain scenario the coordinator disks triggers the fencing driver to ensure only one mini-cluster survives.
{kind=link}
data disks
The disks used in shared storage for VCS are automatically fenced off as they are discovered and configured under VxVM.
Now consider various scenarios and how fencing works to avoid any data corruption.
In case of a possible split brain
As show in the figure above assume that node01 has key “A” and node02 has key “B”.
1. Both nodes think that the other node has failed and start racing to write their keys to the coordinator disks.
2. node01 manages to write the key to majority of disks i.e. 2 disks
3. node02 panics
4. node01 now has a perfect membership and hence Service groups from node02 can be started on node01
In case of a node failure
Assume that node02 fails as shown in the diagram above.
1. node01 detects no heartbeats from node02 and start racing to register its keys on the coordinator disks and ejects the keys of node02.
2. As node01 wins the race forming a perfect cluster membership.
3. VCS thus can failover any service group that’s on the node02 to node01
In case of manual seeding after reboot in a network partition
Consider a case when there is already a network partition and a node [node02] reboots. At this point the node which got rebooted cannot join the cluster due to the gabtab file has specified minimum 2 nodes to be communicating to start VCS and it can’t communicate with other nodes due to network partition.
1. node02 reboots and a user manually forces GAB on node02 to seed the node.
2. node02 detects keys of node01 pre-existing on the coordinator disks and comes to know about the existing network partition. I/O fencing driver thus prevents HAD from starting and outputs an error on the console about the pre-existing network partition.
Summary
VCS ensures data integrity by using all of the below mechanisms.
1. I/O fencing – recommended method. requires scsi3 PGR compatible disks to implement.
2. GAB seeding – prevents service groups from starting if nodes are not communicating. Ensures a cluster membership is formed.
3. jeopardy cluster membership
4. Low priority links – to ensure redundancy in case high priority links fail. In case of a network partition where all high priority links fail, low priority link can be used to form a jeopardy membership by promoting it to a high priority link.